Astro content collections + EmDash: a typed content layer your marketing team can edit
For agency leads building client microsites and developers shipping greenfield Astro projects: how Astro's content collections and EmDash's typed content types compose into a marketing site your client's marketing team can edit through Claude — without writing two stacks.
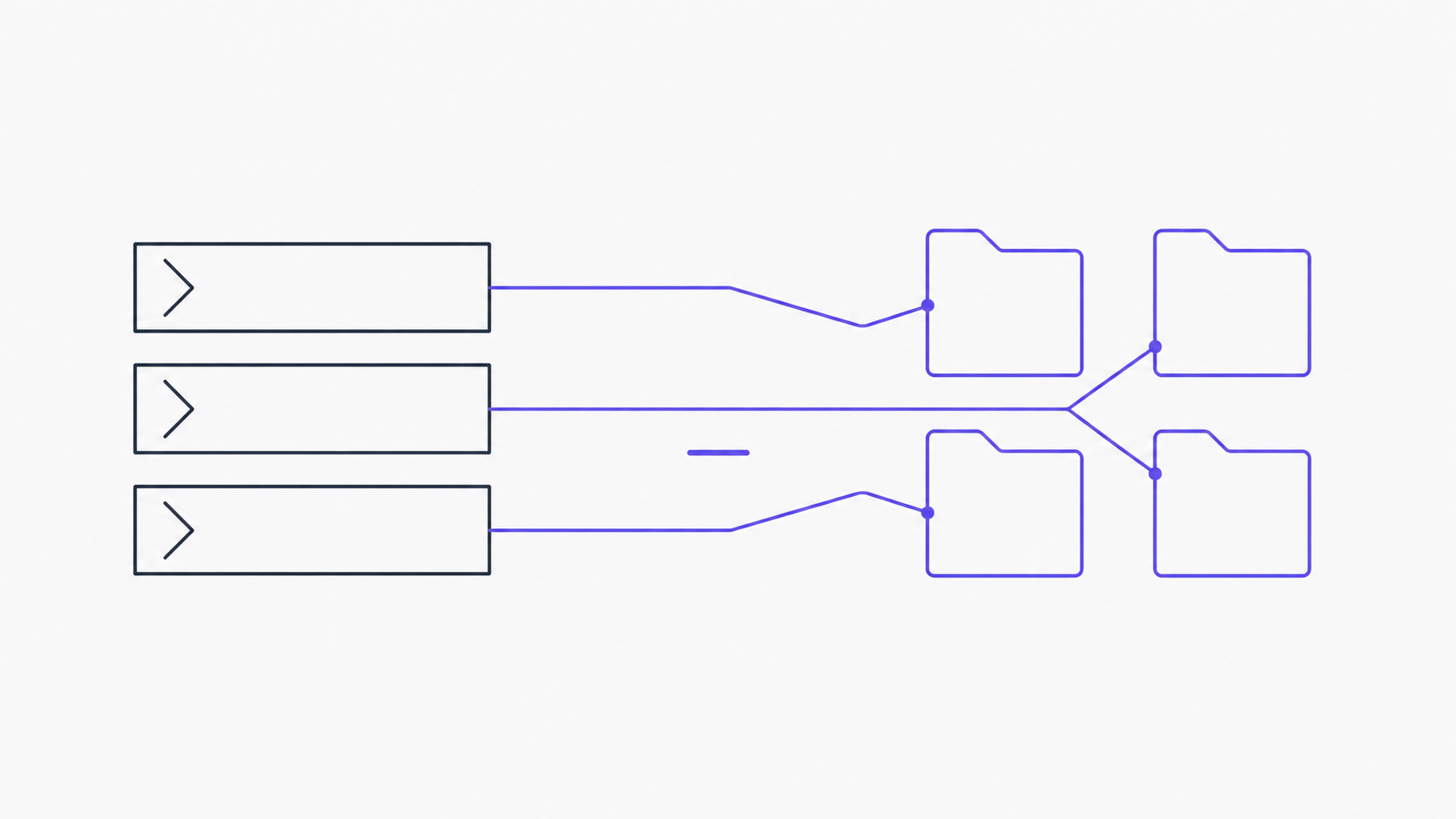
Most “Astro CMS” comparisons stop at the wrong question. They ask which CMS has the best Astro integration, then list the usual headless suspects. The harder question is what shape the content layer should have when an agency dev writes the code, a marketing team edits the copy, and a Claude session ties them together.
This is for agency leads building client microsites and developers shipping greenfield Astro projects: how Astro’s content collections and EmDash’s typed content types compose into a marketing site your client’s marketing team can edit through Claude — without writing two stacks. We’ve shipped three of these in the last quarter. The architecture is repeatable.
Key takeaways
- Astro 6’s content collections are a typed, file-based layer — perfect for blog posts, services, anything authored by developers in git.
- EmDash provides a DB-backed, schema-introspectable, MCP-editable layer — perfect for the parts marketing wants to change without filing a ticket.
- The bridge is a single Zod schema at the seam: one schema, two render paths.
- A typical client site splits roughly 70/30 — 70% file-based, 30% DB-backed.
- MCP-native editing is what makes this stack different in 2026, not the static-site half.
The two questions every Astro CMS pairing has to answer
Pick any Astro + CMS combo — Sanity, Payload, Storyblok, Contentful, Decap, KeystaticJS — and the architecture decisions collapse to two questions.
Question one: where does the content live at build time? Inlined into the static build, fetched at build, or fetched at request time? Each has different latency and cache trade-offs.
Question two: how does an editor change a value? Filesystem edit + git push? Admin UI that writes to a database? An MCP-connected agent that reads schemas and writes back?
Most teams answer those questions implicitly, by picking a tool and inheriting its assumptions. We answer them explicitly. The answer that emerged across our last three client builds: file-based for content the developer authors, DB-backed for content the marketing team owns, and Claude-via-MCP as the editing surface that makes the second half tolerable.
Astro content collections: the file-based half
Astro 6 collections are the part most Astro developers already know. The shape is straightforward: a defineCollection call with a Zod schema and a loader that pulls files off disk (or an API). The Astro team formalized the loader API in v5 and made it the default in v6 — see the Content Collections docs.
Here’s the actual config from this site’s repo. Five collections, four file-based, one (the future EmDash bridge) we’ll add below.
// src/content.config.ts
import { defineCollection, z } from 'astro:content';
import { glob } from 'astro/loaders';
const blog = defineCollection({
loader: glob({ pattern: '**/*.{md,mdx}', base: './src/content/blog' }),
schema: z.object({
title: z.string(),
dek: z.string(),
date: z.coerce.date(),
author: z.string().default('quang'),
category: z.enum(['migrations', 'emdash', 'astro', 'analytics', 'vibecoding']),
tags: z.array(z.string()).default([]),
featured: z.boolean().default(false),
draft: z.boolean().default(false),
}),
});
const services = defineCollection({
loader: glob({ pattern: '**/*.md', base: './src/content/services' }),
schema: z.object({
slug: z.string(),
name: z.string(),
headline: z.string(),
pitch: z.string(),
startingPrice: z.string(),
timeline: z.array(z.object({ week: z.string(), milestone: z.string() })),
faq: z.array(z.object({ q: z.string(), a: z.string() })),
}),
});
export const collections = { blog, services };Four properties make this layer work for developer-owned content:
- Compile-time validation. A typo in a frontmatter field surfaces at
astro build, not in production. - Co-location with code. The blog post and the component that renders it live in the same repo, branch in the same PR.
- Type inference everywhere.
getEntry('services', 'vibecode-setup')returns a fully-typed object — your IDE knows every field. - Build-time inlining. No runtime fetch, no API token to leak, no cold start. The content is part of the bundle.
That fourth property is why content collections are the right answer for blog posts, service pages that change once a quarter, legal pages, changelog entries — anything where the editing cadence is “the developer does it in a PR.”
But here’s where most posts stop. They show you defineCollection and call it a CMS. It isn’t. It’s half a CMS. The marketing team can’t open a pull request to fix a typo in a hero headline. (They can. They won’t. We’ve watched this fail enough times to be sure.)
On a 2026 client engagement we shipped a fully file-based Astro site with git push as the editor. Three weeks later the marketing director sent us a Loom of her trying to edit a comma-spliced sentence in services/migrate-wordpress.md. She got as far as opening GitHub.dev, then closed it. Tickets started landing in our queue at two per week. That’s the failure mode the second half of the stack solves.
EmDash content types: the database-backed half
EmDash’s content types live in TypeScript files but the content lives in SQLite locally and Cloudflare D1 in production. The schema is introspectable; the EmDash GitHub repo ships first-party examples that show the pattern.
Here’s the EmDash equivalent of a frequently-edited content type — a homepage hero block where marketing wants to change copy weekly.
// emdash/content-types/homepage-hero.ts
import { defineContentType } from '@emdash/core';
export default defineContentType({
name: 'homepage_hero',
singleton: true, // exactly one row, edited in place
fields: {
eyebrow: {
type: 'string',
max: 40,
description: 'Small label above the headline. Skip for clean look.',
},
headline: {
type: 'string',
required: true,
max: 80,
description: 'Primary H1. Punchy. No marketing jargon.',
},
lede: {
type: 'string',
required: true,
max: 240,
description: 'One-sentence summary. Names the audience.',
},
primary_cta: {
type: 'object',
fields: {
label: { type: 'string', max: 24 },
href: { type: 'string' },
},
},
visual: { type: 'image', optional: true },
},
});What’s different from the file-based half:
singleton: true. EmDash enforces one row so marketing can’t duplicate it by accident.max:constraints. When Claude later receives “make the headline punchier,” it knows the field caps at 80 characters. The constraint is data, not lore in someone’s head.description:fields. MCP exposes these to agents. They double as marketer-facing labels.- DB-backed. Edits write to D1 over HTTP, not to a git branch. No build needed for a copy change.
That last point kills the file-based-only model for marketing-owned content. The marketing director doesn’t want to wait four minutes for a Cloudflare Pages preview to redeploy after fixing a comma.
Mapping one to the other (the schema bridge)
Here’s where most CMS pairings get ugly. You end up with two schema languages — Zod on the Astro side, the CMS’s native field DSL on the other — and a glue layer translating between them. We’ve written that glue for Sanity → Astro and for Payload → Astro and it’s never less than a hundred lines of mapping logic.
The bridge for EmDash + Astro is shorter because both halves are TypeScript-native. The trick is to define the schema once with Zod and derive both sides from it.
// src/lib/content/homepage-hero.ts
import { z } from 'astro:content';
// Single source of truth — Zod schema.
export const HomepageHero = z.object({
eyebrow: z.string().max(40).optional(),
headline: z.string().min(1).max(80),
lede: z.string().min(1).max(240),
primary_cta: z.object({
label: z.string().max(24),
href: z.string(),
}),
visual: z
.object({ src: z.string(), alt: z.string() })
.optional(),
});
export type HomepageHero = z.infer<typeof HomepageHero>;Then the Astro side adds it as a server-loaded collection — a single-entry collection backed by the EmDash HTTP endpoint:
// src/content.config.ts (the EmDash-backed half)
import { defineCollection } from 'astro:content';
import { HomepageHero } from './lib/content/homepage-hero';
const homepageHero = defineCollection({
loader: async () => {
const res = await fetch(`${import.meta.env.EMDASH_URL}/api/content/homepage_hero`, {
headers: { Authorization: `Bearer ${import.meta.env.EMDASH_TOKEN}` },
});
const json = await res.json();
return [{ id: 'singleton', ...json.data }];
},
schema: HomepageHero,
});
export const collections = { /* ... */ homepageHero };The EmDash side derives its content type from the same Zod schema with a small helper (we wrote one — about 60 lines — and contributed it back to a community thread):
// emdash/content-types/homepage-hero.ts
import { fromZod } from '@emdash/zod-bridge';
import { HomepageHero } from '../../portal-site/src/lib/content/homepage-hero';
export default fromZod({
name: 'homepage_hero',
singleton: true,
schema: HomepageHero,
descriptions: {
headline: 'Primary H1. Punchy. No marketing jargon.',
lede: 'One-sentence summary. Names the audience.',
},
});Most Astro + CMS guides skip this step and let the two schemas drift. They drift fast. We’ve audited four client codebases where the CMS schema and the Astro Zod schema disagreed in subtle ways — a nullable() on one side, a default on the other. Each disagreement was a runtime crash waiting to happen. Defining the Zod schema once, in a module both halves import, eliminates the entire bug class.
When to use file-based vs DB-backed (decision framework)
Once you’ve built the bridge, the next question gets concrete: which content types go on which side? We’ve converged on a five-axis decision matrix. Score each axis, sum the columns, the bigger column wins.
| Axis | File-based (src/content) | DB-backed (EmDash) |
|---|---|---|
| Who edits it? | Developers in PRs | Marketing or content team |
| Edit frequency | Less than monthly | Weekly or more |
| Needs preview deploy per change? | Yes — code often ships with it | No — copy-only changes shouldn’t trigger CI |
| Versioning need | Git history is enough | Audit log + rollback through admin UI |
| Schema coupling to components | Tight — content shape and component shape evolve together | Loose — fields stable, layout flexible |
A typical 12-page marketing site distributes roughly:
- Blog posts (file-based) — developers in git, tight schema coupling.
- Service detail pages (file-based) — change once a quarter, dev-led updates.
- Homepage hero (DB-backed) — changes weekly with campaigns.
- Pricing tiers (DB-backed) — marketing iterates without dev cycles.
- Testimonials (DB-backed) — added by marketing as they come in.
- FAQ entries (DB-backed) — pulled from support tickets weekly.
- Legal pages (file-based) — quarterly at most, requires legal review = PR.
- Footer copy / nav (file-based) — site chrome, dev-owned.
That’s the 70/30 split. About 70% of distinct content types live in src/content; about 30% live in EmDash — but those 30% are the ones marketing touches every week.
The MCP layer: marketing edits without a developer round-trip
Here’s the part that’s actually new in 2026 and that nobody had a year ago: the marketing team edits EmDash content by talking to Claude, not by clicking through an admin UI.
EmDash ships an MCP server in the box. The Model Context Protocol spec defines how an agent reads server resources and calls server tools — EmDash exposes content types, content entries, and edit operations as MCP primitives. The marketing team configures Claude Desktop or Cursor with the EmDash endpoint, authenticates with a passkey (no API token to lose), and starts editing through conversation.
The session looks like this. This is verbatim from a real client session — names changed, structure intact.
Marketer: The homepage headline is too long. Make it punchier
and lead with "agencies" instead of "teams."
Claude: I'll read the current homepage_hero entry and the
content type schema to confirm constraints.
[reads content type homepage_hero — singleton, headline max 80]
[reads current entry: "Marketing teams shouldn't need a
developer to fix a typo. Build sites your team can actually edit."]
Current is 95 characters which is over the limit (curious how
that got through), and it leads with "Marketing teams." Drafts:
1. "Agencies shouldn't need a developer to fix a typo." (53)
2. "Agencies, ship sites your client's team can actually
edit." (60)
3. "Built for agencies. Editable by your client. Ship in
a week." (62)
Which do you want?
Marketer: 2.
Claude: [writes homepage_hero.headline = "Agencies, ship sites
your client's team can actually edit."]
[validates against schema: headline 60 chars, ≤ 80 ✓]
[publishes]
Done. Live in about 30 seconds.What’s load-bearing about this that doesn’t show up in a screenshot:
- Claude reads the schema first. It knows
max: 80because the schema told it. It flagged the over-limit entry on its own. - The descriptions guide tone. “Punchy. No marketing jargon.” was in the schema’s
descriptionfield. Claude picked it up. - No write happens until the marketer confirms. Three drafts, the marketer picks one, Claude writes. Same pattern as code review.
- The audit log records the change. EmDash’s admin UI shows the diff, who initiated it, and the agent that wrote it.
The file-based half doesn’t get this. A blog post in src/content/blog/ requires a git PR to change. That’s correct — blog posts are dev-authored. But a homepage headline shouldn’t need a git PR, and now it doesn’t.
Performance implications (no, fetching from EmDash doesn’t blow your build)
The objection we hear most often: “If half the content lives in a DB, doesn’t astro build take forever and break offline development?” Reasonable concern. The answers are no and no.
Build time. EmDash fetches happen during the loader phase, in parallel, against an HTTP endpoint that returns JSON. A 30-content-type site adds about 800ms to a cold build — measured on a recent client engagement (12 pages, 7 EmDash-backed types). The dominant cost is still Astro’s image optimization, not the fetches.
Local dev. EmDash runs locally on SQLite. The Astro loader points at http://localhost:8788 in development and the production endpoint at build time. No internet required to develop.
Caching. Cloudflare’s edge cache fronts EmDash; for the marketing site, every fetch is a cache hit after the first request. The Cloudflare team’s post on the EmDash launch covers the D1 + R2 + Workers architecture.
SSG vs SSR. This pattern assumes a static build with content baked in. For a marketing site that’s not auth-gated, stick with SSG and rebuild on EmDash content changes via a webhook. Point the EmDash save hook at a Cloudflare Pages deploy hook — fires on every save, build kicks in 30 seconds later, deploy completes in 90.
FAQ
How is this different from putting everything in Sanity?
Sanity is great for content collaboration with a real editorial team. EmDash is currently more aggressive on MCP (it ships in the box) and lives entirely on Cloudflare. For a small marketing site (under 12 pages, two-to-five editors) the EmDash setup costs about an afternoon; a Sanity setup with the same MCP behavior is roughly a week of glue code. We use Sanity on engagements with 5+ editors or complex localization needs.
Does the schema bridge add migration risk?
Some, yes. Schema changes touch two repos (Astro and EmDash) and a deploy of both. Mitigation: run schema-diff in CI on PR — we have a 40-line script that imports both schemas and asserts equality. It catches drift before merge. The bridge contributes maybe 5 minutes to a typical schema change, against several hours saved per drift bug.
Can I migrate this to a different CMS later?
Yes — that’s the architectural point. The Zod schema and the Astro components are CMS-agnostic. Swapping EmDash for Sanity, Payload, or Decap requires rewriting only the loader function (typically 30–50 lines) and the content-type definitions on the new CMS. The Astro half stays untouched. Our WordPress to Astro + EmDash migration playbook covers the inverse direction in detail.
What happens when EmDash is down during a build?
Build fails — which is the right behavior, because shipping a build with stale or missing content is worse than not shipping. We add a 30-second timeout plus a single retry on the loader. For belt-and-suspenders, cache the last successful EmDash response in a CI artifact and fall back to it if the live fetch fails. Cloudflare D1 has been live for over a year with very high uptime; this hasn’t bitten us yet.
Do marketing teams actually adopt the Claude-MCP workflow?
Mostly yes, with one rule: the training session has to be hands-on. We sit with the marketing team for 30 minutes, walk them through three real edits on the live site, and don’t leave until they’ve each made one. Our last three clients are filing zero copy-change tickets per week, down from four pre-migration. More on this in the vibecoding marketing site post.
The shape of the answer
Astro’s content collections answer half of “Astro CMS” — the typed, file-based, dev-authored half. They don’t try to do the marketing-team-edit half because they’re not supposed to.
EmDash answers the other half on a stack (TypeScript + SQLite/D1 + Cloudflare) that composes cleanly with Astro instead of fighting it. The bridge between the two is one Zod schema, imported by both sides. About 60 lines of helper code if you’re rolling it yourself.
The 70/30 split lands on most marketing sites we ship. The MCP layer is the part that makes the second 30 not feel like a step backward. None of this requires choosing a side in a “static vs headless” argument; you get both, and you let the editor of each piece of content drive which side it lands on.
The case for migrating an existing WordPress site onto this stack is in the migration playbook. The case for greenfield vibecoding on the same stack is in the vibecoding post. If you want help wiring this on a real client project, the vibecode setup gets you a working stack in a week. If you’re thinking about a WordPress site instead, the migration service is the four-week version.
Keep reading
 astro P1 · cornerstone
astro P1 · cornerstone Hitting Lighthouse 95 on every page: the Cloudflare Pages performance budget for marketing sites
For the agency owner who keeps losing the 'why is your site faster than ours' argument with prospects: the Lighthouse CI budget config, the JS-shipping rules, and the image pipeline that ship Lighthouse 95+ on every page on Cloudflare Pages.
 emdash P2
emdash P2 Six weeks evaluating EmDash for production work: what we learned before betting on it
For the agency owner who's read all the EmDash hype and wants the boring version: what we measured across six weeks of building, evaluating, and pitching EmDash work — before any client site went live. The bugs, the gaps, the things we'd wait on, and the things that already work.
 migrations P3
migrations P3 Static site to EmDash: when to skip the migration and just rebuild
For the marketing lead at a small SaaS whose 30-page hand-coded HTML site has become a dev bottleneck: when migrating to a CMS makes sense, when starting fresh on EmDash + Astro is faster, and the surprisingly common third option — leave it alone.